Ever clicked on a link and found that the page doesn’t exist? This post is for you.
1. Manage your expectations
2. Check search engine caches for recent deleted pages
3. Try the Internet Archive’s Wayback Machine for much older pages
4. Other relevant posts on this blog
5. Troubleshooting and alternative options
1. Manage your expectations
Although there are several tools to uncover deleted pages there’s no guarantee that you’ll find the page you’re looking for. Not all websites are captured or sometimes the particular page you want hasn’t been saved. Best to always approach these searches as a pleasant surprise if you find anything.
2. Check search engine caches for recently deleted pages
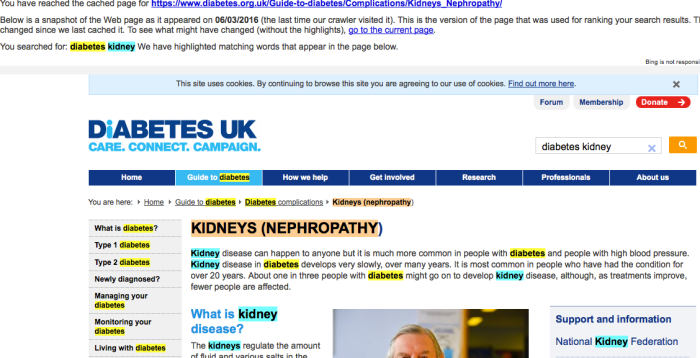
Search engines index websites by crawling through all their links, they sometimes keep a cached copy of the page. When you type in a search term and press enter you’re shown a list of possible hits and if you click on the main link you’ll go straight to the page. On Google and Bing (and I’m sure many other search engines) this tiny little arrow will show you a copy that the search engine has saved in its cache. No arrow = no available cache.
![]()
Cached pages are continually overwritten and updated so the cache of a page deleted today may disappear in a few days so this option only works for recently deleted pages (sometimes it works for tweets too, try searching for the person’s profile and see if anything shows up.
If you find what you’re looking for you might like to save a copy of the webpage as a file (eg in Firefox this is File / Save Page As…) or save it as a screenshot.
3. Try the Internet Archive’s Wayback Machine for much older pages
If you don’t find a copy using a search engine then try the Wayback Machine. This tool captures all sorts of websites automatically but people can also ask it to save a copy of a website (from now onwards) if it’s not currently there.
Go to https://archive.org/

and type in the address of the website (homepage) or particular link (blog post etc) that you’re interested in, then press enter on your keyboard or click anywhere outside the text box.

Either you’ll see a page telling you nothing’s been saved (see 5. Troubleshooting and alternative options) or you’ll see something like this.
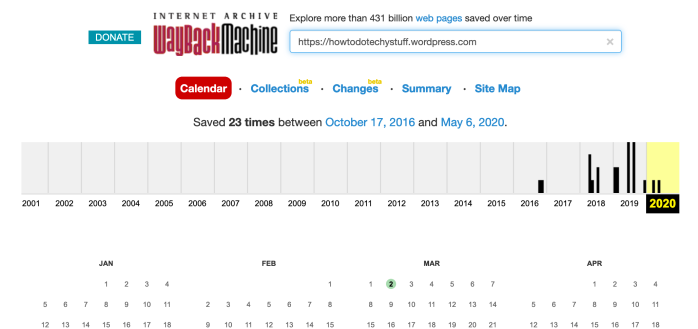
This tells me that pages from this very blog have been saved 23 times in three and a half years and I can use the year tabs at the top to scroll back. Each black bar represents a month, its length indicates the number of copies made. Here’s 2016 – two copies saved – one on October 17th (highlighted) and another on 14 November.
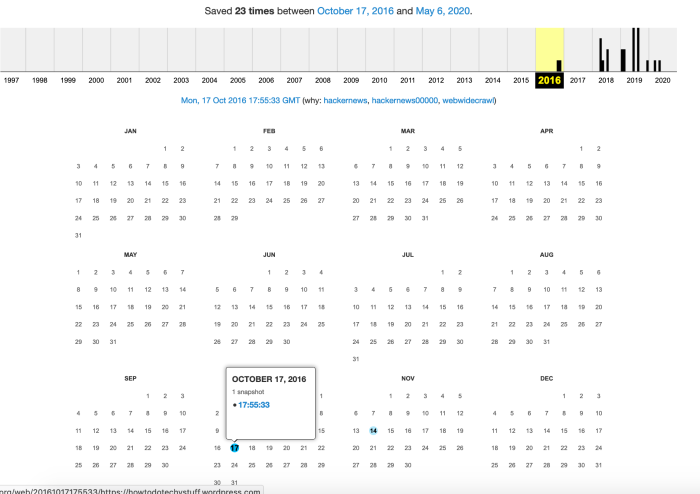
To access the saved copy hover over the the blue dot on the date it was collected and a moment later the little pop up will show with a link to one or more snapshots taken. The timestamp is the link to a copy of the site / page taken at that time on that date. Click to visit, the example for this website is below – you can see that the numbers in the link relate to the year, month, day and time
https://web.archive.org/web/20161017175533/https://howtodotechystuff.wordpress.com/
There’s a video showing the full process below (includes a slight delay as the archived page takes longer to open).
4. Other relevant posts on this blog
- “Forensic” Twitter – getting evidence for use in court etc (18 July 2015) – lots of advice on finding and capturing information with a focus on Twitter
- Google cache (& other search engines): finding deleted pages or seeing your words on the page in colour (12 March 2016) – a sort of precursor to this page
- Taking a screenshot (16 October 2016) – how to capture what’s on your screen, on several platforms
- Occasional workaround for reading US websites which are skittish about EU visitors, GDPR and cookies (28 July 2018) – a different sort of missing page. US news sites aren’t always available in the UK / EU, sometimes you can sneak up on them
- A slightly forensic Twitter example – in which a key tweet is now unavailable (3 March 2019) – finding evidence that a tweet existed, though not whether or not it had been doctored.
5. Troubleshooting and alternative options
Sometimes a page you’re after hasn’t been captured and that’s the end of the search. You might be given the option to look at all pages within a site so that’s worth a look. I’ve also been presented with a page that looks like this – it’s displayed while you’re redirected to something. Before closing the tab you might as well wait and see where you end up.

Page I was trying to reach: https://web.archive.org/web/20130929051516/https://twitter.com/JoBrodie/followers
Page I ended up being taken to: https://web.archive.org/web/20171002100900/https:/twitter.com/login?redirect_after_login=%2FJoBrodie%2Ffollowers – you can see where you’re going to be redirected to on the page (though you won’t know what it looks like until you’ve been redirected there).
There are other services like the Wayback Machine, here’s a selection.
It’s also helpful to search Twitter and search engines for references to the page you’re after. Even if your page has gone people might have taken screenshots and shared them via Twitter or in blog posts / newspaper articles.